
안녕하세요!
오늘은 빅분기 실기 합격 후기를 들고왔습니다! ㅎㅎ
일단 실기의 출제문항 및 배점에 대해서 알아보도록 하겠습니다.
출제문항 및 배점
시험은 총 180분 동안 치뤄집니다. 또한, 90분이 지난 이후 퇴실이 가능합니다.
| 직무분야 | 정보통신 | 중직무분야 | 정보기술 | 자격종목 | 빅데이터 분석기사 |
| ○ 직무내용 대용량의 데이터 집합으로부터 유용한 정보를 찾고 결과를 예측하기 위해 목적에 따라 분석기술과 방법론을 기반으로 정형/비정형 대용량 데이터를 구축, 탐색, 분석하고 시각화를 수행하는 업무를 수행한다. |
|||||
| 실기검정방법 | 통합형(필답형, 작업형) | 시험시간 | 180분 | ||
데이터자격시험 사이트에는 다음과 같이 나와있지만,
제가 실기 시험을 본 토대로 말씀드리면 다음과 같습니다.
| 시험 종류 | 문항수 | 배점 |
| 필답형 | 10문제 (단답형) | 3점씩 총 30점 |
| 작업형1 | 3문제 (python or R 전처리 능력 평가) | 10점씩 총 30점 |
| 작업형2 | 1문제 (머신러닝 모델링 분류 혹은 회귀 문제) | 총 40점 |
빅분기 실기의 세부 내용에 대해서 말씀드리면 아래와 같습니다.
시험 주요 내용
| 실기과목명 | 주요항목 | 세부항목 | 세세항목 |
| 빅데이터 분석실무 |
데이터 수집 작업 | 데이터 수집하기 |
|
| 데이터 전처리 작업 | 데이터 정제하기 |
|
|
| 데이터 변환하기 |
|
||
| 데이터 모형 구축 작업 |
분석모형 선택하기 |
|
|
| 분석모형 구축하기 |
|
||
| 데이터 모형 평가 작업 |
구축된 모형 평가하기 |
|
|
| 분석결과 활용하기 |
|
응시자격 및 합격기준
빅분기 필기를 합격한 분들은 실기를 볼 수있으며,
작업형 유형을 통틀어서 최종 60점 이상만 얻으면 합격이고, 과락기준은 없습니다!
사용교재
일단 저는 R은 사용한지 너무 오래돼서 자주 사용하는 python을 선택했습니다.
그런데 python 교재는 너무 python 기본개념만 들어있다고 판단되어 굳이 교재는 구매하지 않았습니다. (사실 python 교재를 구매했지만 한번도 안보고 그대로 팔았습니,,ㄷㅏ,, ㅎㅎ)
대신, 같이 시험 보는 친구들에게 모의고사를 받아서 아래 책의 실전 모의고사 3회만 풀었습니다.

공부방법
저는 머신러닝 모델링도 해 본 경험이 있고 평상시에 python 전처리도 많이 하는 편이기 때문에
친구에게 받은 실전 모의고사 2회분을 푼 것을 제외하고 공부를 하지 않았습니다 ㅎㅎ
아 그리고 꿀팁을 하나 드리자면,
전날 파이썬 머신러닝 라이브러리를 정리해서 이를 외우고 가시는걸 추천드립니다!
저는 아래와 같이 정리했습니다! ㅎㅎ
######## 사용할 라이브러리 모음
import pandas as pd
import numpy as np
# 데이터셋 불러오기
from sklearn.datasets import load_boston
# train, test 나누기
from sklearn.model_selection import train_test_split
# Scaling
from sklearn.preprocessing import MinMaxScaler
# 분류
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.svm import svm
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix
# 회귀
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.svm import svm
from sklearn.metrics import mean_squared_error
# 경고 무시
import warnings
warnings.filterwarnings(action = 'ignore')기출문제 복기
이제 기출문제 복기를 해드리려고 합니다! ㅎㅎ
필답형
*순서는 확실하지 않습니다.
- 은닉층 노드 계산
- 향상도 정의
- 앙상블 정의
- SVM 정의
- 평균연결법
- 명목형 변수 정의 (순서형과 비교)
- 분포를 모를 때, 데이터를 0~1 사이로 변환하는 것은? (Min-Max Scaling)
*여기서부턴 정답이 뭔지 정확히 기억이 나질 않아 문제를 적어보겠습니다! ㅎㅎ
- 그룹화를 의미하는 데이터 변환을 뭐라하는가
- 예시 : 일별 데이터 그룹화 -> 월별, 분기별 데이터로 변환
- (빈칸) A 학교의 영어점수 60점과 B학교의 영어점수 60점은 같은 60점이지만 학교가 다르기 때문에 같은 점수라고 볼 수없다. 이는 데이터의 ( )이 다르기 때문이다.
- (빈칸) 군집분석 진행 시 데이터의 ( ) 를 고려하는 것이 중요하다 (정확히 기억이 안나네요,,ㅠ)
작업형 제 1유형
1. [캘리포니아 집값 데이터] 데이터의 결측값을 제거한 후, 처음부터 순서대로 70%를 추출하여 특정 변수의 Q1 값 구하기
* 주의할점 : 정답 제출 시, 정수형으로 제출해야하기 때문에 int()를 잊으시면 안됩니다!
데이터
import pandas as pd
import numpy as np
housing = pd.read_csv("housing.csv")
housing.dropna(inplace= True)
train = housing.iloc[:int(housing.shape[0]*0.7)]
result = np.percentile(train['housing_median_age'], 25)
print(int(result)) # 정답 : 192. [연도별 나라별 유병률 데이터] 데이터 중 2000년도에 전체 국가 유병률의 평균보다 큰 나라 수를 구하라.
유병률 데이터의 경우 데이터를 못구해서 코드만 올리겠습니다.
* 데이터가 정확히 어떻게 생겼는지 기억이 안나서 코드가 확실하지 않을 수 있습니다,,
import pandas as pd
data = pd.read_csv('data.csv') # index : date / 열 : 국가 / 데이터 : 유병률
data.reset_index(inplace = True)
train = data[data['index'] == 2000]
train_t = train.transpose()
train_t.reset_index(drop = True)
train_t.columns = ['country', 'data']
result = len(train_t[train_t['data'] > train_t['data'].mean()])
print(result)
3. [타이타닉 데이터] 각 열의 결측치 비율을 확인 한 후, 결측율이 가장 높은 변수 명을 추출해라.
캐글 url 주소: https://www.kaggle.com/c/2019-1st-ml-month-with-kakr/overview
위의 주소에서 trian, test 데이터를 다운로드 해주시면 됩니다.
import pandas as pd
titanic = pd.read_csv("train.csv")
# 결측치 비율
train = pd.DataFrame(titanic.isnull().sum()/len(titanic), columns = ['null_ratio'])
train.reset_index(inplace = True)
result = train[train['null_ratio'] == train['null_ratio'].max()]['index'].reset_index(drop = True)[0]
print(result) # 정답 : Age
작업형 제 2유형 [머신러닝 분류]
travel insurance 데이터를 활용해서 보험가입여부를 예측하라.
저는 간단하게 모델링 진행하고 나왔습니다.
데이터 전처리 -> 데이터 스케일링 -> 랜덤포레스트, 그래디언트 부스팅 -> 앙상블 -> 결과 제출로 진행했고, 결과는 약 80% 정도 나왔던 것 같습니다! 더 열심히 모델링 해볼까 하다가 충분한것 같아서 그냥 나왔습니다 ㅎㅎ
결과
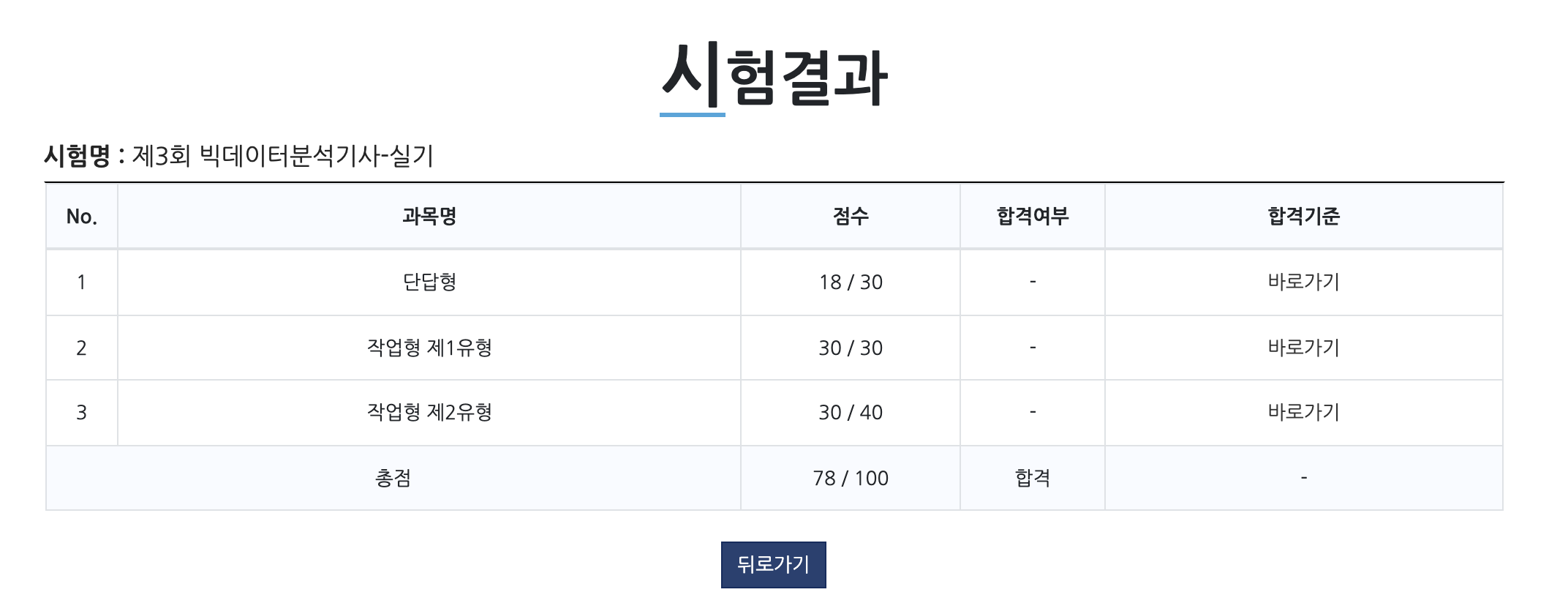
포스팅을 마치겠습니다! 감사합니다 :)
'etc > 자격증' 카테고리의 다른 글
| [빅분기] 제 3회 빅데이터 분석기사 필기 합격 후기 및 꿀팁 (0) | 2021.12.23 |
|---|---|
| [ADsP] 제 29회 데이터분석 준 전문가 ADsP 합격 후기 및 꿀팁 이론&기출문제 (1) | 2021.12.11 |
| [SQL] 제40회 SQL 개발자 시험 후기 및 합격 꿀팁, 자격검정 실전문제 (6) | 2021.12.11 |